Our research focuses on structural characterization of membrane proteins and de novo protein design in order to understand biological processes relevant to human disease and develop novel therapeutics.
Protein design

Proteins are complex macromolecules that serve a myriad of roles within organisms. De novo protein design is made possible due to our growing atomistic and mechanistic understanding of protein biochemistry and folding as well as protein-ligand interactions. These, together with rapidly accelerating progress in machine learning, allow us to design proteins with novel functionality completely from scratch. In the DeGrado Lab, we use our collective knowledge to design from first principles both water- and lipid-soluble proteins. Some examples of our design success include metalloproteins, membrane protein design, and ligand-selective binding proteins. We also are designing proteins that release cytotoxic and cell-penetrating peptides upon proteolytic activation in vivo.
Currently, we are implementing our design capabilities towards the development of new computational tools with a wide variety of applications. We utilize physics-based, statistics-based, and machine learning approximations to develop new methods to improve the design of protein interactions with small-molecules, metals, and proteins.
Membrane protein design

A major aim of our research is to elucidate membrane protein structure/function through protein design. Design of de novo functional membrane proteins has traditionally proven to be challenging, but with recent advances in structural biology and protein structure prediction, we are rapidly making progress in this field. From the design of a Zn2+/H+ antiporter (Rocker) to the design of proton-selective channels, we are shedding light on how natural membrane proteins assemble and function. In previous studies, we use structural bioinformatics to build pentameric bundles and showed that apolar packing alone can define helical assembly in the membrane. From these designs, we then built functional proton channels. Ongoing studies focus on the role of water molecules within the pore in proton transport, and transport of a variety of other small molecules.
We are also interested in membrane proteins as targets for drug development. With the recent advent of COVID-19, our attention has turned to the Envelope (E) protein, a membrane-bound viral ion channel, or viroporin, on SARS-CoV-2. In previous work with the influenza A M2 channel, through structural biology and functional studies, we were able to get a complete picture of how this particular viroporin selectively moves protons to start the viral pathogenesis process. This work guided the development of targeted small-molecule therapeutics that overcome the problem of rising drug resistance. Now, we extend this work to the discovery and development of novel therapeutics for the E protein of SARS-CoV-2. By uncovering the molecular mechanisms by which the E protein functions through structural and functional studies, we can work to design potent drug candidates that target this viroporin.
Metalloprotein Design

Many enzymes use metal ions and metallocofactors (such as heme) to catalyze challenging transformations that are key to life. These proteins demonstrate exquisite control of their primary, secondary, and tertiary structure to perform regio- and stereo-selective transformations with high selectivity. Our lab has used de novo protein design to create minimal models of metalloproteins that catalyze important transformations, such as O2-mediated small molecule oxidations. We have used these design principles to build de novo proteins that tightly bind natural and abiological metallocofactors with sub-Å precision and are currently using traditional physics based and generative neural-net based models to enable metalloenzyme design. These studies allow us to test and extend our understanding of the interplay between protein and metal ions in fine-tuning reactivity. For further reading, check out our latest review.
Chemical Biology and Medicinal Chemistry

We have also collaborated with other UCSF scientists to identify small molecules to address unmet medical need. Our current efforts are directed towards pharmaceutical treatments for organ fibrosis, asthma/COPD and liver cancer through the discovery of integrin antagonists (with Dean Sheppard and Aparna Sundaram) and acid ceramidase inhibitors (with Jennifer. Chen). Integrins are heterodimeric membrane proteins, which connect extracellular protein ligands to cytoplasmic alpha-smooth muscle actin (aSMA). The force generated by aSMA contraction is transmitted through integrins to the bound extracellular ligands, playing an important in a number of biological and pathophysiological processes. For example, transforming growth factor beta is expressed as a latent precursor that is simultaneously bound to the extracellular matrix and one of a number of integrin subtypes, including avb1 and avb6. In stiff fibrotic tissue this results in activation of TGF-b in an actin-dependent manner. This pathological feed-forward loop can be inhibited using small molecule inhibitors of the appropriate integrins. For example, our lab developed inhibitors of avb1, which lead to the formation of Pliant, a company that is pursuing clinical trials of integrin antagonists for treatment fibrosis.
We are also examining the role of integrin-mediated force generation in the exaggerated airway narrowing and contraction observed in severe asthma and COPD. We are designing integrin antagonists to disrupt the actin-extracellular bridge between airway smooth muscle and the extracellular matrix. In animal models, these antagonists decrease the transmission of force and they mitigate hyper-responsiveness, while leaving normal contractile responses intact.
Chemical tools can greatly improve our understanding of protein structure and function. We design novel probes based upon SuFEx (Sulfur-Fluoride Exchange) chemistry and site-specific incorporation of isotopes to interrogate proteins on atomic scale.
With Ian Seiple and Charley Craik we also develop novel approaches to design of protease activated antibiotics and cell penetrating peptides.
Structural and Chemical Biology approaches to neurodegenerative diseases

A wide variety of neurodegenerative diseases are characterized by protein misfolding. For example, tauopathies, including Alzheimer’s disease, chronic traumatic encephalopathy, progressive supranuclear palsy, corticobasal degeneration, etc, are diseases characterized by the deposition of misfolded tau fibrils. Although sharing the same protein sequence, the structures (also known as conformational strains) of misfolded tau proteins differ in each of these diseases. Similarly, different fibril conformations of the neuronal protein alpha-synuclein has been linked to diseases including Parkinson’s disease, dementia with Lewy bodies, and multiple system atrophy. We seek to gain a molecular and cellular understanding of pathogenic protein misfolding using a combination of biochemical/biophysical and cell biology methods. In particular, we are developing small fluorescent molecules whose spectra are highly characteristic of distinct conformational strains. Using machine learning, we are able to differentiate a large number of different conformational strains in vitro and in human brain samples. We also developing genetically encoded proteins that serve as sensors of the formation of conformational strains.
Bacterial sensing
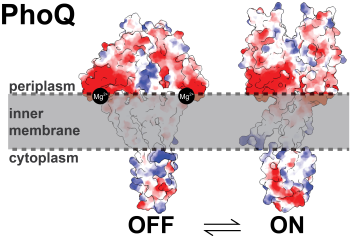
Transmembrane signal transduction is an essential mechanism by which cells sense and respond to their environment. In bacteria, this process is mediated by two-component systems that consist of a transmembrane histidine kinase to sense environment cues and cognate response regulator to control cellular responses. These systems are numerous and diverse, controlling growth, survival, and pathogenicity. To understand the mechanisms of signal transduction, we study the structure using structural and biophysical techniques (x-ray crystallography and cryo-EM) with biochemical and in-cell assays. In addition to studying native histidine kinase mechanisms, we are also applying de novo protein design to explore and re-engineer histidine kinase signaling and specificity.